Grafana mimir에 대한 전반적인 자료 수집 내용을 정리해봤습니다.
Grafana Labs에서 Cortex 개발을 주도하고 있었지만, Mimir를 출시하면서 Cortex는 더 이상 개발하지 않습니다.
https://grafana.com/blog/2020/01/16/how-cortex-is-evolving-to-ingest-1-trillion-samples-a-day/
Mimir는 Time Series DataBase로, 수평적 확장이 가능하여 많은 수의 series를 쉽게 다룰 수 있습니다.
현재는 Prometheus 형식의 메트릭을 저장할 수 있으며, 목표는 모든 time series에 대한 핸들링이므로 InfluxDB나 opentelemetry, Datadog을 포함한 메트릭까지 확장할 계획입니다.
https://grafana.com/blog/2022/03/30/announcing-grafana-mimir/
여러 개의 ingester가 metric을 중복 수집하고, storage에서 compaction(압축)을 통해 중복 제거, 저장합니다.
Grafana Mimir Operator and user guide
https://grafana.com/docs/mimir/latest/operators-guide/
Grafana Mimir에 Data를 넣는 방식
prometheus의 remote_write를 통해 데이터를 넣을 수 있습니다. 따라서, prometheus의 remote_write를 지원한다면 mimir에 데이터를 넣을 수 있다고 생각하면 됩니다.
제가 테스트할 때 사용한 것은 prometheus와 grafana-agent입니다.
아래는 그 예시입니다.
1. Configure Prometheus to write to Grafana mimir
prometheus.yaml에 아래 내용 정의
remote_write:
- url: http://<ingress-host>/api/v1/push
2. Configure Grafana Agent to write to Mimir
grafana agent에 아래 내용 정의
remote_write:
- url: http://<ingress-host>/api/v1/push
Grafana에서 Grafana mimir 데이터 보는 방법
Grafana Datasource에 Database type을 Prometheus로 선택하고, Mimir의 url을 등록합니다.
아래는 url 예시입니다.
http://<ingress-host>/prometheus
multi tenancy를 사용하고 있다면, Custom HTTP header를 설정해야 합니다.
X-Scope-OrgId 헤더에 tenant ID를 정의하는 방식입니다.
Grafana mimir helm chart
helm repo add grafana https://grafana.github.io/helm-charts
helm fetch grafana/mimir-distributed
Grafana mimir를 모니터링 = metamonitoring
Grafana mimir helm chart에 metamonitoring 부분이 self monitoring을 의미합니다.
metaMonitoring:
serviceMonitor:
enabled: true
grafanaAgent:
enabled: true
installOperator: true
metrics:
additionalRemoteWriteConfigs:
- url: "http://mimir-nginx.mimir-test.svc:80/api/v1/push"
Grafana mimir Components
https://grafana.com/docs/mimir/latest/get-started/about-grafana-mimir-architecture/
Mimir component에 대한 문서를 번역해봤습니다.
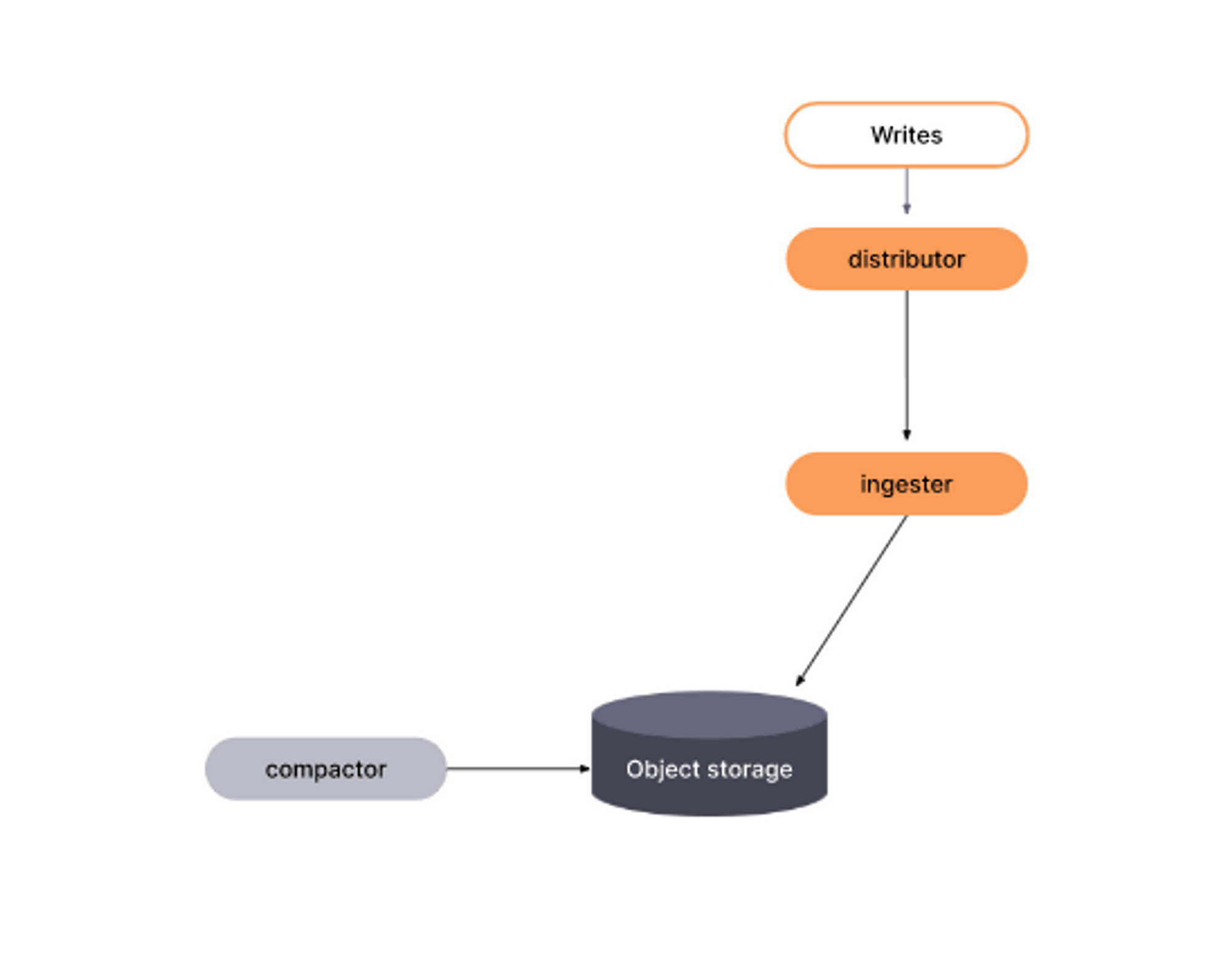
Grafana mimir write path

Ingester가 Distributor로부터 들어오는 샘플을 받는다. (각 push 요청은 tenant에 속한다.)
Ingester는 받은 샘플을 로컬 디스크에 저장된 특정 Tenant별 TSDB에 추가한다.
받은 샘플은 in-memory와 WAL(write-ahead log) 둘 다에 가지고 있는다.
(Ingester가 갑자기 종료되면, WAL이 in-memory series를 복구하는 데 도움을 줄 수 있다.)
테넌트별 TSDB는 특정 테넌트의 첫 샘플을 받게 되면, 각 ingester에 느리게 생성된다.
새로운 TSDB block이 생성되면, in-memory 샘플은 주기적으로 디스크에 flush되고, WAL은 truncate(데이터를 전부 삭제하고 사용하고 있던 공간을 반납)된다.
이 주기의 default 값은 2시간이다.
새로 생성된 block마다 장기 storage에 업로드되고, ingester은 blocks-storage.tsdb.retention-period에 설정된 주기에 따라 만료될 때까지 block을 가지고 있는다.
이를 통해 Querier와 store-gateway가 새로운 block을 storage로부터 찾아내고 해당 block의 index-header를 다운받을 때까지의 충분한 시간을 얻을 수 있다.
WAL을 효과적으로 사용하기 위해, 그리고 Ingester가 갑자기 종료됐을 때 in-memory series를 복구할 수 있도록 만들기 위해, WAL을 Ingester 실패에서도 살아남을 수 있는 영구 디스크에 저장한다.
(ex. AWS EBS)
(그래서 Ingester가 Statefulset+PVC로 배포되는 것임)
WAL은 head로부터 압축된 TSDB block과 같은 위치에 저장되며, 따로 분리할 수 없습니다.
아래는 ingester pod에 접속해서 tsdb와 WAL을 확인해 본 내용
Grafana mimir read path
Grafana Mimir에 들어오는 쿼리들은 query-frontend에 도착한다. query-frontend는 긴 시간 범위의 쿼리를 더 작게 여러 개로 분할한다.
query-frontend는 results cache를 확인한다. 만약 쿼리의 결과가 cache되어 있으면, query-frontend는 cache된 결과를 반환한다. results cache에서 얻지 못한 쿼리는 query-frontend 내 in-memory queue에 넣는다.
만약, 옵션으로 query-scheduler라는 구성요소를 구동시키면, 이 queue는 query-frontend가 아닌 query-scheduler에 유지된다.
querier는 worker처럼 queue로부터 쿼리를 가져오는 역할을 한다.
querier는 store-gateway와 ingester에 연결하여 쿼리를 실행하기 위해 필요한 모든 데이터를 가져온다.
querier가 쿼리를 실행하면, 집계를 위해 결과를 query-frontend에 반환한다. query-frontend는 집계된 결과물을 client에 반환한다.
➡️ results cache가 어디에 있는지 확인해봤는데, mimir helm chart에서 results-cache를 활성화시키면 mimir.memcached.statefulSet 에 적용되는 것으로 보임 근데, mimir config를 살펴보면 chunks-cache도 memcache에 되는 것으로 보임
이전 버전의 helm chart에서는 memcached에 내용을 넣는거였고, 최신 버전에서는 results-cache가 따로 생긴 것

Component - Compactor
compactor는 data block을 압축시켜서 쿼리 성능을 높이고 장기 스토리지 사용량을 줄입니다.
테넌트의 여러 블록을 하나로 압축시켜서 청크 중복 제거를 하고, 그에 따라 인덱스 크기가 줄어서 스토리지 비용이 절감되고 쿼리 속도가 증가하는 것입니다.
또한, retention 기간에 포함되지 않는 block을 삭제합니다. (보관 기간이 지난 것)
https://grafana.com/docs/mimir/latest/references/architecture/components/compactor/
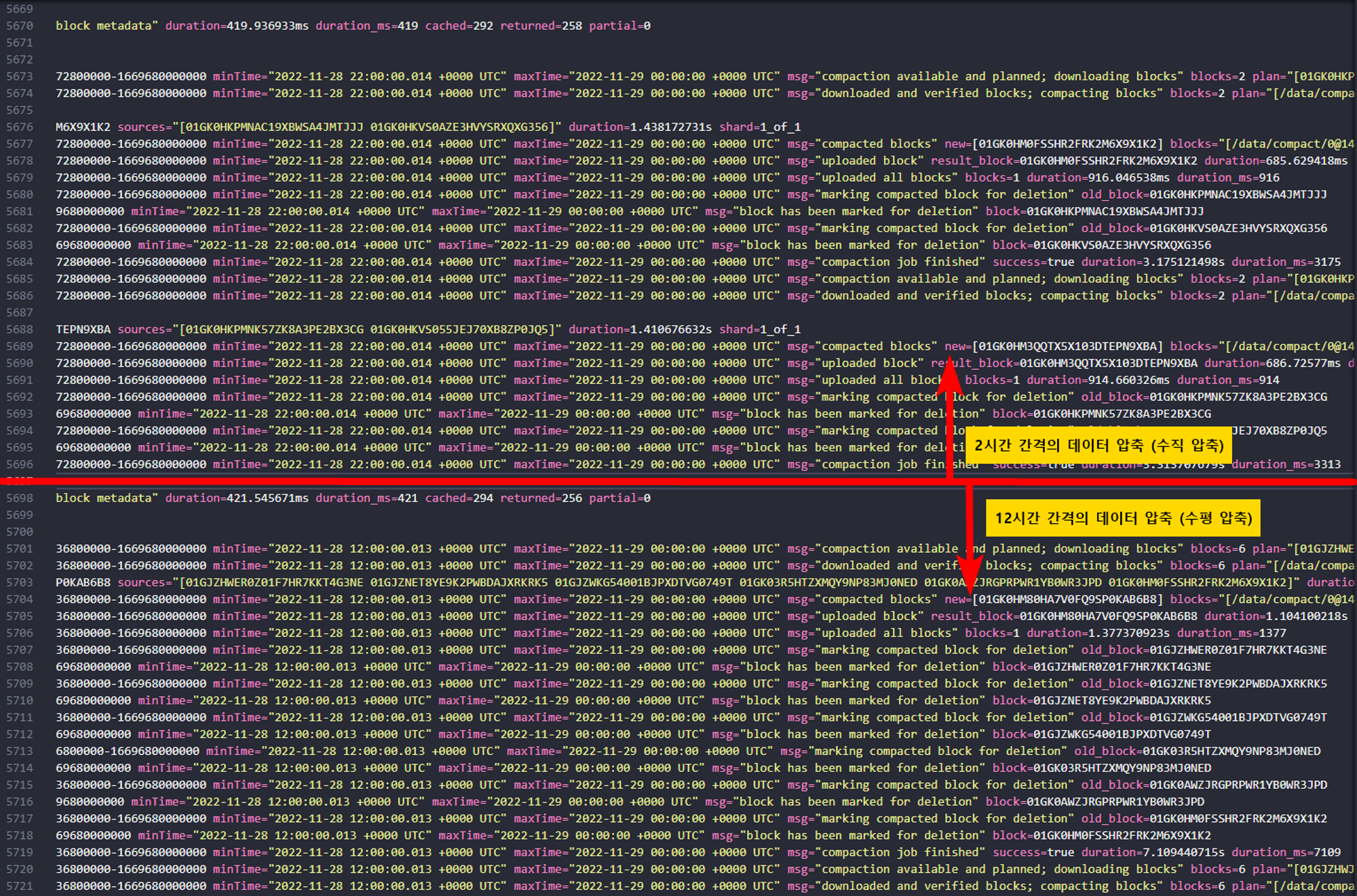
두 가지 압축 방식이 있습니다.
- 수직 압축(Vertical compaction)
- 같은 time range에 대하여 (default는 2시간) 여러 테넌트에 저장된 block을 중복 제거를 통해 하나로 압축시킵니다.
- 즉, 하나의 tenant, 특정 time range에 대하여 ingester 숫자 만큼 존재했던 data block을 하나로 감소시킵니다.
- 수평 압축(Horizontal compaction)
- 수직 압축 이후에 진행되는 과정입니다.
- 인접한 range에 있는 여러 개의 block을 하나의 더 큰 block으로 압축합니다.
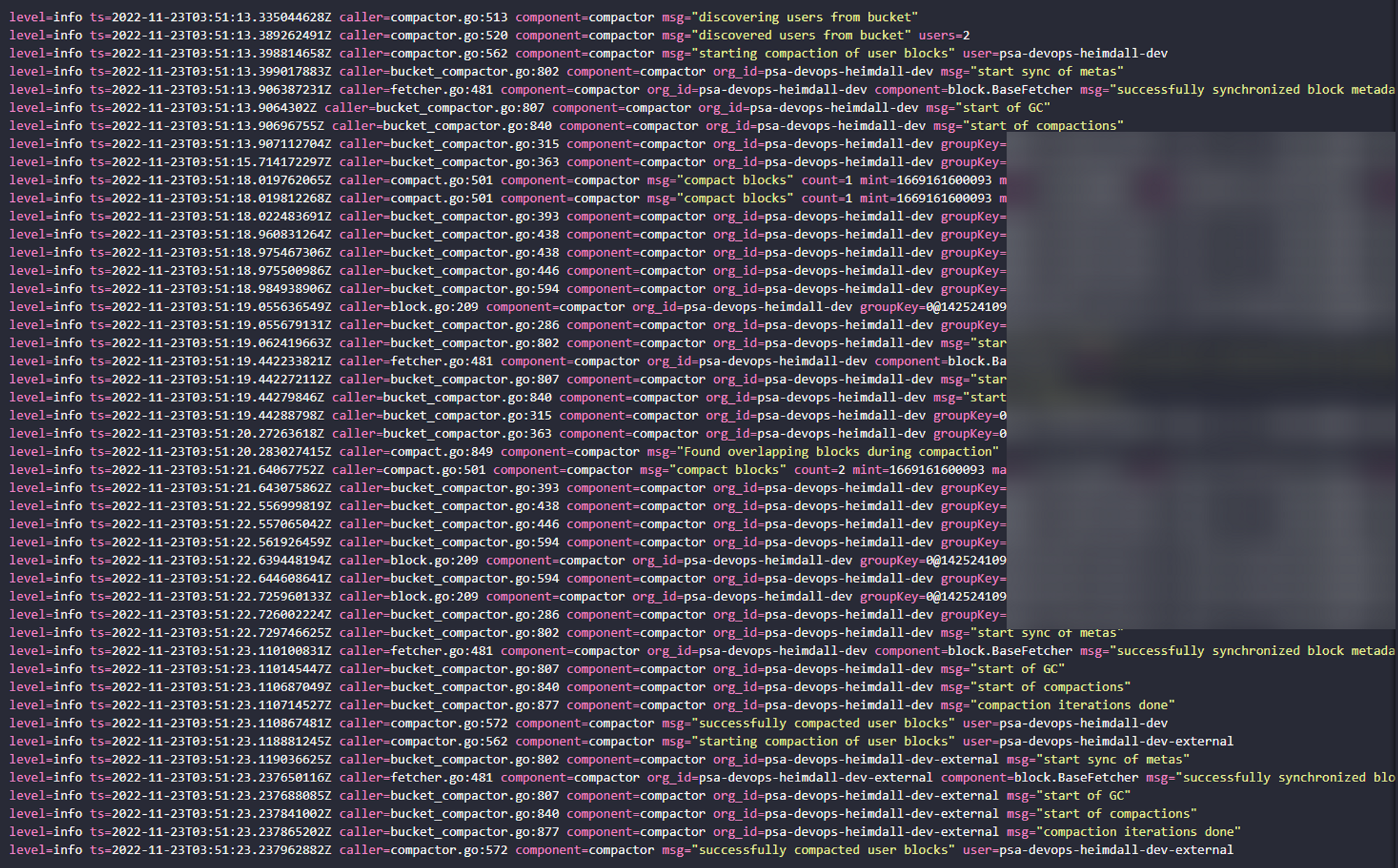
compactor log 뽑아보면, 아래와 같이 2시간 간격으로 압축이 진행되는 것을 확인할 수 있습니다.
압축이 진행되는 시간은, 정확한 기준은 아직 파악중이지만,
예를 들어 2시 00분 ~ 4시 00분 데이터 블록이 5시 50분에 압축되었습니다.

수평압축은 12시간 간격의 데이터를 압축시키는 것 같습니다. (로그상에서 확인)
Grafana Mimir HTTP API Reference
https://grafana.com/docs/mimir/latest/references/http-api/
Mimir에 Opentelemetry
https://grafana.com/docs/mimir/latest/configure/configure-otel-collector/
'Monitoring' 카테고리의 다른 글
| Prometheus를 push 방식으로 쓰기 (0) | 2023.08.31 |
|---|---|
| Grafana-agent for uploading PrometheusRule to mimir (0) | 2023.08.31 |
| Opentelemetry - Collector filtering span (0) | 2023.08.28 |
| Opentelemetry - auto instrumentation with specific libraries (0) | 2023.08.28 |
| Opentelemetry - auto instrumentation (0) | 2023.08.28 |